Analizador Léxico.
Concepto 1:
Un analizador léxico y/o analizador léxico gráfico (en ingles scanner) es la primera fase de un compilador consistente en un programa que recibe como entrada el código fuente de otro programa (secuencia de caracteres) y produce una salida compuesta de tokens (componentes léxicos) o símbolos. Estos tokens sirven para una posterior etapa del proceso de traducción, siendo la entrada para el analizador sintáctico (en inglés parser).
La especificación de un lenguaje de programación a menudo incluye un conjunto de reglas que definen el léxico Estas reglas consisten comúnmente en expresiones regulares que indican el conjunto de posibles secuencias de caracteres que definen un token o lexema.
En algunos lenguajes de programación es necesario establecer patrones para caracteres especiales (como el espacio en blanco) que la gramática pueda reconocer sin que constituya un token en sí.
Concepto 2:

Analizador léxico.
Se encarga de buscar los componentes léxicos o palabras que componen el programa
fuente, según unas reglas o patrones.
La entrada del analizador léxico podemos definirla como una secuencia de caracteres.

El analizador léxico tiene que dividir la secuencia de caracteres en palabras con significado
propio y después convertirlo a una secuencia de terminales desde el punto de vista del
analizador sintáctico, que es la entrada del analizador sintáctico.
El analizador léxico reconoce las palabras en función de una gramática regular de manera
que sus NO TERMINALES se convierten en los elementos de entrada de fases
posteriores. En LEX, por ejemplo, esta gramática se expresa mediante expresiones
regulares.
Funciones del Analizador Léxico
- Convierte el programa fuente en una cadena de tokens
- Para reconocer el token usa un patrón, una regla que describe como se forman las cadenas que corresponden a un token.
- Salta comentarios y espacios en blanco (tabuladores, saltos de línea...)
- Tener el registro de la línea del archivo fuente que está siendo analizada
- Genera mensajes de error léxico, y se recupera del error
- Convierte los valores literales al tipo que corresponda
- Si la entrada debe obedecer a un formato, verifica el formato Ej. Fortran, Cobol
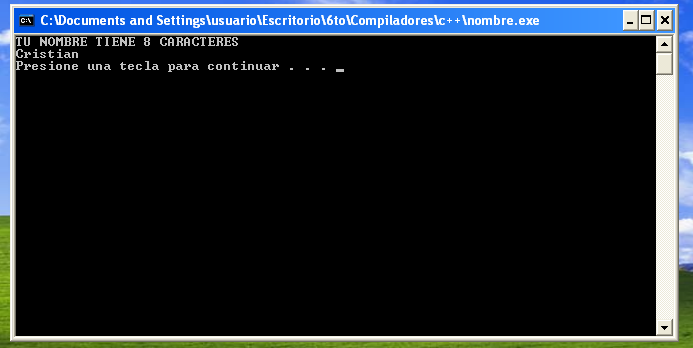
Ejemplos:


Representación de los componentes de un Analizador Léxico.
En
la fase de análisis, los términos componentes léxicos (token), patrón y
lexemase emplean con significados específicos. Un analizador léxico,
inicialmente lee loslexemas y le asigna un significado propio.
•Componente
léxico es la secuencia lógica y coherente de caracteres relativo auna
categoría: identificador, palabra reservada, literales
(cadena/numérica),operador o carácter de puntuación, además de que un
componente léxico puedetener uno o varios lexemas.
•
Patrón es una regla que genera la secuencia de caracteres que puede
representar
a un determinado componente léxico (expresión regular).
•
Lexema es una cadena de caracteres que concuerda con un patrón que describe
un
componente léxico (valor de cadena).
Ejemplo
de una cadena de código: const pi = 3.1416;

El
analizador léxico recoge información sobre los componentes léxicos en
susatributos asociados.
Los
tokens influyen en las decisiones del análisis sintáctico, ylos atributos, en
la traducción de los tokens.
En la práctica los componentes léxicos suelen
tener solo un atributo.Para efectos de diagnostico, puede considerarse tanto el
lexema para unidentificador como el numero de línea en el que se encontró por
primera vez.

Analizador semántico.
Concepto 1:
Se compone de un conjunto de rutinas independientes, llamadas por los analizadores morfológico y sintáctico.
El análisis semántico utiliza como entrada el árbol sintáctico detectado por el análisis sintáctico para comprobar restricciones de tipo y otras limitaciones semánticas y preparar la generación de código.
En compiladores de un solo paso, las llamadas a las rutinas semánticas se realizan directamente desde el analizador sintáctico y son dichas rutinas las que llaman al generador de código. El instrumento más utilizado para conseguirlo es la gramática de atributos.
En compiladores de dos o más pasos, el análisis semántico se realiza independientemente de la generación de código, pasándose información a través de un archivo intermedio, que normalmente contiene información sobre el árbol sintáctico en forma linealizada (para facilitar su manejo y hacer posible su almacenamiento en memoria auxiliar).
En cualquier caso, las rutinas semánticas suelen hacer uso de una pila (la pila semántica) que contiene la información semántica asociada a los operandos (y a veces a los operadores) en forma de registros semánticos.
Concepto 2:
Los programas que se compilan no son solamente cadenas de símbolos sin ningún significado que pueden ser aceptadas como correctas o no por una máquina abstracta. El lenguaje no es más que el vehículo por el cual se intenta transmitir una serie de instrucciones a un procesador para que éste las ejecute produciendo unos resultados.
Por ello, la tarea del compilador requiere la extracción del contenido semántico incluido en las distintas sentencias del programa.
Por todo ello, se hace necesario dotar al compilador de una serie de rutinas auxiliares que permitan captar todo aquello que no se ha expresado mediante la sintaxis del lenguaje y todo aquello que hace descender a nuestro lenguaje de programación de las alturas de una máquina abstracta hasta el nivel de un computador real. A todas estas rutinas auxiliares se les denomina genéricamente análisis semántico.
El análisis semántico, a diferencia de otras fases, no se realiza claramente diferenciado del resto de las tareas que lleva a cabo el compilador, más bien podría decirse que el análisis semántico completa las dos fases anteriores de análisis lexicográfico y sintáctico incorporando ciertas comprobaciones que no pueden asimilarse al mero reconocimiento de una cadena dentro de un lenguaje.
La fase de análisis semántico revisa el programa fuente para tratar de encontrar errores semánticos y reúne la información sobre los tipos para la fase posterior de generación de código. En ella se utiliza la estructura jerárquica determinada por la fase de análisis sintáctico para identificar los operadores y operandos de expresiones y proposiciones.
Un componente importante del análisis semántico es la Verificación de Tipos. Aquí, el compilador verifica si cada operador tiene operandos permitidos por la especificación del lenguaje fuente.

Ejemplos:
int a,b,c;
a/(b+c^2)
El árbol sintáctico es: /
---------
| |
a +
---------
| |
b ^
---------
| |
c 2
De la instrucción declarativa, la tabla de símbolos y el analizador morfológico obtenemos los atributos de los operandos: /
---------
| |
a +
int ---------
| |
b ^
int ---------
| |
c 2
int int
Propagando los atributos obtenemos: / int
---------
| |
a + int
int ---------
| |
b ^ int
int ---------
| |
c 2
int int
Si la expresión hubiera sido a/(b+c^-2)
El árbol sintáctico sería el mismo, sustituyendo 2 por -2. Sin embargo, la propagación de atributos sería diferente: / real
---------
| |
a + real
int ---------
| |
b ^ real
int ---------
| |
c -2
int int
En algún caso podría llegar a producirse error (p.e. si / representara sólo la división entera).Si la expresión hubiera sido
int a,b,c,d;
a/(b+c^d)
El árbol sintáctico sería el mismo, sustituyendo 2 por d. Sin embargo, la propagación de atributos sería incompleta: / {int,real}
---------
| |
a + {int,real}
int ---------
| |
b ^ {int,real}
int ---------
| |
c d
int int
Segundo ejemplo:
real a;
int b,c;
a:=b+c
El árbol sintáctico es: :=
---------
| |
a +
real ---------
| |
b c
int int
Existen dos conversiones posibles: := real := real
--------- ---------
| | | |
a + real a + int
real --------- real ---------
| | | |
b c b c
int int int int
Representación de los componentes.